Interested in contributing to Gorilla LLM or curious to learn more? Check out the Github repository and the README.md for more information.
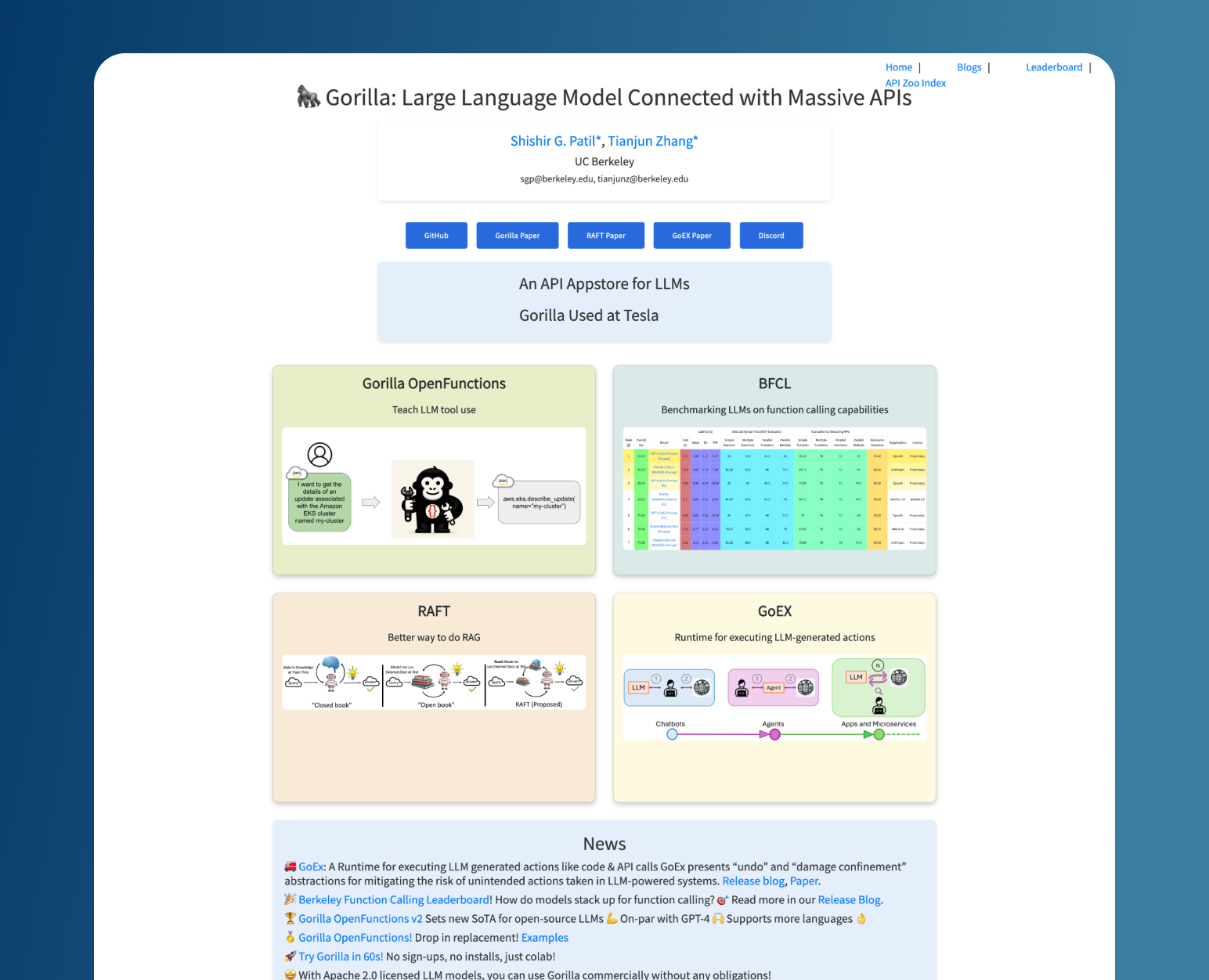
What is Gorilla LLM?
Gorilla LLM is an open-source large language model (LLM) that connects with an extensive array of tools and services accessed via APIs (i.e. Hugging Face, PyTorch Hub, 1000+ 3rd party APIs). This new paradigm allows users to ask Gorilla to execute a task in natural language – the LLM would (1) understand the most relevant API to use and (2) return a well-formed function to take an “action” that accomplishes the user’s task.
📢 Excited to release Gorilla🦍 Gorilla picks from 1000s of APIs to complete user tasks, surpassing even GPT-4! LLMs need to interact with the world through APIs, and Gorilla teaches LLMs APIs. Presenting Gorilla-Spotlight demo🤩 Webpage: gorilla.cs.berkeley.edu
To put the power of Gorilla in perspective, imagine you’re planning a trip to Cancún, Mexico with your family. You might prompt Gorilla with “I’m planning a trip to Cancún, Mexico for a family of four individuals and I’m looking for a place to stay for 5 nights during my stay. Can you find me some places to stay along with the price per night?”. Gorilla would understand the problem and constraints and use a fitting API (i.e. Airbnb, Expedia, etc) to find a list of locations along with the price per night for each place and return the information back to the user. If the user likes a certain place and wants to make a booking, they would also be able to prompt that in natural language or through a seamless Generative UI experience.
Gorilla is a retrieval-aware finetuned LLaMA-7B model that can operate in two different modes: zero-shot or retrieval-mode. Zero-shot does not append any additional context into the prompt besides the initial user-query. And, retrieval-mode uses a standard retriever like Okapi BM25 or GPT-Index to obtain the most relevant and up-to-date pieces of API documentation from Gorilla’s API Database (aka. API Zoo).
API Zoo is an actively maintained corpus of API documentation curated by the community of contributors on the Gorilla repository. In addition to including the standard machine learning APIs from Hugging Face and PyTorch Hub, it includes popular 3rd party APIs like Servicenow, Datadog, and Salesforce.
How was Gorilla LLM trained?
Gorilla uses a novel finetuning method known as Retriever-Aware Training, or RAT for short. But before I dive into how RAT works, I will briefly discuss how the finetuning dataset was curated. The original authors (Patil, Shishir, et al.) collected and filtered online model cards from Hugging face, Pytorch Hub, and Tensorflow Hub across a range of domains – Computer Vision, Natural Language Process, Audio, Reinforcement Learning – and converted the models into a standardized JSON format with the structure below. The resulting dataset contained 1,645 APIs - 925 from Hugging Face, 626 from Tensorflow Hub v2, and 94 from Torch Hub.
{domain, framework, functionality, api_name, api_call, api_arguments, environment_requirements, example_code, performance, and description.}For each hub, six (Instruction, API) pairs were hand-curated, resulting in 18 data points (note: these were the only hand-generated data in the entire data curation process). Taking inspiration from the work pioneered in Self-Instruct (Wang, Yizhong, et al.), for the 1,645 API calls, 3/6 (Instruction, API) pairs were randomly sampled to generate 10 (Instruction, API) pairs using GPT-4. In total, 16,450 (Instruction, API) pairs were generated with GPT-4. The data was then post-processed where each data point was converted into a user-agent chat-style conversation, which was then used to finetune LLaMA-7B.
Now back to Retriever-Aware Training - what exactly is it? This methodology is similar to Retrieval-Augmented Generation (RAG) paradigms, but modified to be used in fine-tuning with a retriever. In addition to being trained without a retriever (zero-shot), Gorilla LLM was fine-tuned with a retriever which appended "Use this API documentation for reference: <retrieved_API_doc_JSON>" to the user prompt. The purpose of adding this additional prompt was for the LLM to “learn” to use the latter half, which includes the relevant documentation to accomplish the task, to answer the first half of the question. RAT has some benefits and drawbacks worth evaluating before you choose to adopt this fine-tuning recipe into your own workflow:
How to measure hallucinations?
When working with LLMs, hallucinations are an inevitable phenomenon where the model outputs a nonsensical or inaccurate response. In the context of Gorilla, where it returns an API call, there is a key distinction between the semantics of what can be classified as an inaccuracy vs. a hallucination. An inaccuracy is defined as when the model selects the wrong API for the user’s task. For example, if the user wants a computer vision model to classify cats vs. dogs, and the model returns a ServiceNow API call for opening up a ticket, this is an inaccuracy because the API returned is not made up. In contrast, hallucinations are when the model makes up or “dreams” of an API that does not exist.
Gorilla uses Abstract Syntax Trees (ASTs) to measure hallucinations for LLM generations. ASTs were invented back in the 1960s by Donald Knuth and are used to represent programs in a tree-like structure for the purpose of checking the equivalency between two programs. Gorilla uses a method called AST Sub-Tree Matching to compare the API returned by the model to the reference AST constructed from the source dataset.
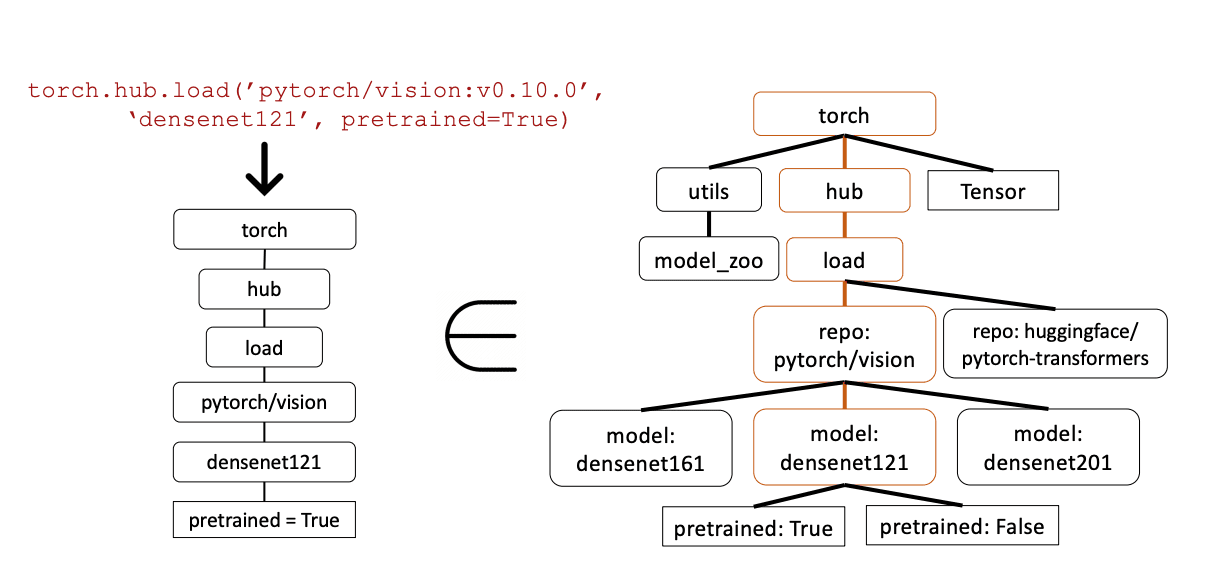
Above is an example from the Gorilla Paper. The left side is an example response of the model and the right is a subtree of the torch API from the dataset. Since the left subtree lives within AST of the dataset, there is a match, signifying that the API returned by Gorilla is correct.
Conclusion
Gorilla is paving the way for designing powerful AI agentic workflows capable of collecting and assembling data and taking actions in the “real world”. I would like to end this article with a tweet by Andrew Ng, where he talks more about the future of LLMs and tool-use. He cites Gorilla as a recommended source to learn more about equipping LLMs with powerful tools and APIs. If you would like to get involved with the Gorilla project, check out the Github repository.
Tool use, in which an LLM is given functions it can request to call for gathering information, taking action, or manipulating data, is a key design pattern of AI agentic workflows. You may be familiar with LLM-based systems that can perform a web search or execute code. Some of
References
Patil, Shishir, et al. Gorilla: Large Language Model Connected with Massive APIs.
Wang, Yizhong, et al. “Self-Instruct: Aligning Language Model with Self Generated Instructions.” ArXiv (Cornell University), 20 Dec. 2022, https://doi.org/10.48550/arxiv.2212.10560.